MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,属于Oracle旗下产品,是最流行的关系型数据库管理系统之一。
端口是3306。
规范
- 不区分大小写
- 以
;结尾,支持多行输入 - 通过tab和空格提高可读性
- 注释:
- 单行注释:
-- - 多行注释:
/* .... */
- 单行注释:
数据库
创建数据库
以默认的编码方式创建:
CREATE DATABASE <数据库名称>;创建时,指定编码方式:
CREATE DATABASE <数据库名称> CHARACTER SET <编码方式>;不存在时才创建:
CREATE DATABASE IF NOT EXISTS <数据库名称>;存在时不会报错,有warning
使用:SHOW WARNINGS;查看。
查看数据库
查看所有数据库:
SHOW DATABASES;查看当前数据库:
SELECT DATABASE();为
NULL时,说明未使用数据库可查看编码
SHOW CREATE DATABASE <数据库名称>;
使用数据库
即进入或切换到某个数据库中:
USE <数据库名称>;
修改数据库
修改编码方式
ALTER DATABASE <数据库名称> CHARACTER SET <编码方式>;修改名称
修改起来比较麻烦
MySQL 5.1.23之前的旧版本使用:RENAME DATABASE <旧名称> TO <新名称>;都可以用的方法:
此方法实际上将所有表从一个数据库移动到另一个数据库。
如:把”user”改为”data”-- 1 创建新的数据库"data" CREATE DATABASE data; -- 2 使用RENAME TABLE命令修改表名,将表移动到新的库里 RENAME TABLE user.table1 TO data.table1; -- 假如有多个表的话,应该重复使用RENAME命令 -- 3 完成后删除旧库”user“ DROP DATABASE user;表很多时,使用linux脚本,需要根据需要修改一下:
#!/bin/bash mysql -uroot -p<密码> -e 'create database if not exists <新数据库名称>;' list_table=$(mysql -uroot -p<密码> -Nse "select table_name from information_schema.TABLES where TABLE_SCHEMA='<旧数据库名称>'") for table in $list_table do mysql -uroot -p<密码> -e "rename table <旧数据库名称>.$table to <新数据库名称>.$table" done # mysql 参数: # -e, --execute=name # 执行mysql的sql语句 # -N, --skip-column-names # 不显示列信息 # -s, --silent # 一行一行输出,中间有tab分隔
删除数据库
DROP DATABASE <数据库名称>;
和创建一样,可以加上if exists
表
数据类型
可两篇文章:
约束条件
NOT NULL- 指示某列不能存储 NULL 值。UNIQUE- 保证某列的每行必须有唯一的值。PRIMARY KEY- NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。FOREIGN KEY- 保证一个表中的数据匹配另一个表中的值的参照完整性。CHECK- 保证列中的值符合指定的条件。DEFAULT- 规定没有给列赋值时的默认值。其他字段
AUTO_INCREMENT- 默认AUTO_INCREMENT 的开始值是 1,每条新记录递增 1。修改默认值ALTER TABLE 表名 AUTO_INCREMENT=100
创建表
CREATE TABLE <表名称>(
<字段名> <类型> [约束条件],
<字段名> <类型> [约束条件],
<字段名> <类型> [约束条件],
);
如:
CREATE TABLE Persons
(
Id_P int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (Id_P) //PRIMARY KEY约束
)
CREATE TABLE Persons
(
Id_P int NOT NULL PRIMARY KEY, //PRIMARY KEY约束
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
查看表信息
查看表结构
DESC <表名称>; -- 或者 SHOW COLUMNS FROM <表名称>;查看当前数据库的所有表
SHOW TABLES;查看建表语句
SHOW CREATE TABLE <表名称>;
修改列
用于在已有的表中添加、删除或修改列。
添加 ADD
ALTER TABLE <表名称> ADD <字段名> <类型> [约束条件];或
ALTER TABLE <表名称> ADD <字段名> <类型> [约束条件], ADD <字段名> <类型> [约束条件], ADD <字段名> <类型> [约束条件], ADD <字段名> <类型> [约束条件];默认是添加到最后,但可以指定位置。
FIRST:添加最前
AFTER <字段名>:添加指定字段之后
例子:ALTER TABLE data ADD username VARCHAR(20) AFTER id; -- 在data中往id后面添加一个username字段 -- FIRST的使用方法类似删除 DROP
ALTER TABLE <表名称> DROP <字段名>; -- 和添加一样可以多行DROP修改 MODIFY
主要修改原列的类型或约束条件
同样可以用FIRST和AFTER <字段名>,代表的是修改到哪里。ALTER TABLE <表名称> MODIFY <字段名> <类型> [约束条件]; -- 和添加一样可以多行MODIFY修改字段名 CHANGE
ALTER TABLE <表名称> CHANGE <旧字段名> <新字段名> <类型> [约束条件]; -- 和添加一样可以多行CHANGE
删除表
DROP TABLE <表名称>
复制表
CREATE TABLE <表1名称> (SELECT * FROM <表2名称>);
可以把表2的数据复制到表1中,但不能复制约束性条件。
记录
增加记录
单行
INSERT INTO <表名称>(行1, 行2...) VALUES(值1, 值2...);多行,注意只有一个VALUES:
INSERT INTO <表名称>(行1, 行2...) VALUES (值1, 值2...), (值1, 值2...), (值1, 值2...);不写
(行1, 行2...)这一部分的话,默认一一对应除了以上方法外,还可以用SET为每一行附上相应的值
INSERT INTO <表名称> SET 行1=值1, 行2=值2...;
修改记录
假如没有筛选的话,就给全部都修改了。可以用WHERE筛选。
-- 修改一个或多个
UPDATE <表名称> SET 行1=值1, ...;
-- 加上WHERE
UPDATE <表名称> SET 行1=值1, ... WHERE ...
删除记录
假如没有筛选的话,就给全部删除了。相当于清空。
DELETE FROM <表名称>;
清空:
TRUNCATE TABLE <表名称>;
先把表删除,然后再建一个。与DELETE FROM相比,TRUNCATE的效率更快,因为DELETE FROM是把记录逐条删除的。
查询(单表)
查询执行的顺序
FROM –> WHERE –> SELECT –> GROUP BY –> HAVING –> ORDER BY –> LIMIT
SELECT
SELECT 语句用于从数据库中选取数据。结果被存储在一个结果表中,称为结果集。*:SELECT * FROM <表名称>把表中所有的信息都取出来DISTINCT:SELECT DISTINCT <字段名> FROM <表名称>去重AS:SELECT <字段名> AS <别名> FROM <表名称>别名如:
SELECT data+10 AS "数据" FROM <表名称>
WHERE
WHERE子句用于过滤记录。运算符 描述 例子 =等于 SELECT * FROM data WHERE id = 1;<>不等于。某些 SQL中,可写成 != 参考 =的>大于 参考 =的<小于 参考 =的>=大于等于 参考 =的<=小于等于 参考 =的BETWEEN在某个范围内 SELECT * FROM data WHERE id BETWEEN 2 AND 4; -- 2到4,两边都是闭区间LIKE使用通配符搜索 %:0 个或多个字符,_:一个字符,[charlist]:字符列中的任何单一字符,[^charlist]或[!charlist]:不在字符列中的任何单一字符;如:WHERE 字段名 LIKE 'a_%_%'以“a”开头且长度至少为3个字符的值IN指定针对某个列的多个可能值 SELECT * FROM data WHERE id IN (1,3,6);AND- - OR- - NOT- - IS- IS NUll或IS NOT NULLORDER BY
以某一字段名进行排序。
如:SELECT * FROM data ORDER BY name;
可以指定升序(ASC)、降序(DESC),默认升序。
SELECT * FROM data ORDER BY name DESC;GROUP BY
- 行名:
SELECT name FROM data GROUP BY name; - 数字:指的是SQL语句中出现的字段顺序,如:
SELECT sum(id), name FROM data GROUP BY 2;2代表额是第二个字段name - 与聚合函数结合,如上面例子中的sum。
注:如果在SELECT中的列,没有在GROUP BY中出现,那么这个SQL是不合法的。报错:“this is incompatible with sql_mode=only_full_group_by”
- 行名:
HAVING
分组后的过滤。
用WHERE的地方可以用HAVING,HAVING可以使用聚合函数,而WHERE不可以使用聚合函数。SELECT name FROM data GROUP BY name HAVING SUM(id) > 5;聚合函数
- COUNT(字段名):统计行数
- SUM(字段名):求和
- AVG(字段名):求平均数
- MAX(字段名):求最大值
- MIN(字段名):求最小值
- LENGTH(字段名):返回长度
LIMIT与OFFSET
可用于分页,只取一部分。
LIMIT:只有一个数时,表示取几条数据;两个数(a, b)时,表示取[a+1, a+b]这个区间的数据
OFFSET:值跳过多少条数据SELECT * FROM Customer LIMIT 10; --检索前10行数据,显示1-10条数据 SELECT * FROM Customer LIMIT 1,10; --检索从第2行开始,累加10条id记录,共显示id为2....11 SELECT * FROM Customer LIMIT 10 OFFSET 1; --检索从第2行开始,累加10条id记录,共显示id为2....11 SELECT * FROM Customer LIMIT 5,10; --检索从第6行开始向前加10条数据,共显示id为6,7....15注意
当数据很大,上百万的时候,使用LIMIT … OFFSET ..的方式进行分页十分浪费资源且耗时长。最好是结合WHERE使用,如:-- LIMIT ... OFFSET .. SELECT * FROM data LIMIT 10 OFFSET 80000001; -- 10 rows in set (12.80 sec) -- WHERE SELECT * FROM data WHERE id > 80000000 LIMIT 10; -- 10 rows in set (0.01 sec)REGEXP
使用正则表达进行匹配。查询时,需要搭配WHERE或HAVING使用。SELECT name FROM data GROUP BY name HAVING name REGEXP 'f$'; SELECT name FROM data WHERE name REGEXP 'f$' GROUP BY name;
多表查询
内连接查询
两个表之间有交集且要用到两个表的数据时,可以使用内连接查询。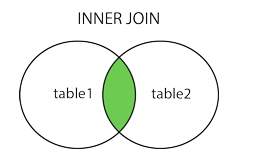
user表:
+----+--------+
| id | name |
+----+--------+
| 1 | 小明 |
| 2 | 小红 |
| 3 | 小林 |
+----+--------+
log表:
+----+-------------+------+
| id | longinCount | uid |
+----+-------------+------+
| 1 | 2 | 3 |
| 2 | 19 | 1 |
| 3 | 5 | 2 |
+----+-------------+------+
-- 使用INNER JOIN ... ON ...
-- 格式:SELECT * FROM <表1名> INNER JOIN <表2名> ON <表1名>.id = <表2名>.uid;
-- 注:表1、表2的顺序可变
SELECT * FROM user INNER JOIN log ON user.id=log.uid;
-- 也可以直接查询
-- 格式:SELECT * FROM <表1名>, <表2名> WHERE <表1名>.id = <表2名>.uid;
SELECT * FROM user, log WHERE user.id=log.uid;
/*
+----+--------+----+-------------+------+
| id | name | id | longinCount | uid |
+----+--------+----+-------------+------+
| 3 | 小林 | 1 | 2 | 3 |
| 1 | 小明 | 2 | 19 | 1 |
| 2 | 小红 | 3 | 5 | 2 |
+----+--------+----+-------------+------+
*/
-- 排序并使用别名
SELECT user.id AS UID, user.name AS Name, log.longinCount FROM user, log WHERE user.id=log.uid ORDER BY user.id;
/*
+-----+--------+-------------+
| UID | Name | longinCount |
+-----+--------+-------------+
| 1 | 小明 | 19 |
| 2 | 小红 | 5 |
| 3 | 小林 | 2 |
+-----+--------+-------------+
*/
外链接查询
LEFT JOIN
LEFT JOIN 关键字从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
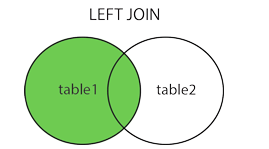
name1:
+----+--------+------------+
| id | name | loginCount |
+----+--------+------------+
| 1 | 小明 | 23 |
| 2 | 小红 | 12 |
| 3 | 小刚 | 53 |
| 4 | 小吕 | 123 |
+----+--------+------------+
name2:
+----+--------+-----------+
| id | name | comment |
+----+--------+-----------+
| 1 | 小刚 | 直男 |
| 2 | 小红 | 白富美 |
| 3 | 小明 | 学霸 |
+----+--------+-----------+
用法:
/*
SELECT * FROM <表1名>
LEFT JOIN <表2名>
ON <表1名>.<某字段> = <表2名>.<某字段>;
*/
-- 例子
SELECT * FROM name1 LEFT JOIN name2 ON name1.name=name2.name;
/*
+----+--------+------------+------+--------+-----------+
| id | name | loginCount | id | name | comment |
+----+--------+------------+------+--------+-----------+
| 3 | 小刚 | 53 | 1 | 小刚 | 直男 |
| 2 | 小红 | 12 | 2 | 小红 | 白富美 |
| 1 | 小明 | 23 | 3 | 小明 | 学霸 |
| 4 | 小吕 | 123 | NULL | NULL | NULL |
+----+--------+------------+------+--------+-----------+
*/
-- 没有匹配到,就为NULL
-- 美化一下
SELECT name1.id, name1.name, name2.comment FROM name1 LEFT JOiN name2 ON name1.name=name2.name ORDER BY name1.id;
/*
+----+--------+-----------+
| id | name | comment |
+----+--------+-----------+
| 1 | 小明 | 学霸 |
| 2 | 小红 | 白富美 |
| 3 | 小刚 | 直男 |
| 4 | 小吕 | NULL |
+----+--------+-----------+
*/
RIGHT JOIN
RIGHT JOIN 关键字从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。把LEFT JOIN的表1、表2调换顺序,就是REGHT JOIN。
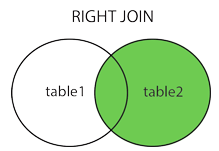
SELECT * FROM name2 right JOIN name1 ON name1.name=name2.name;
/*
+------+--------+-----------+----+--------+------------+
| id | name | comment | id | name | loginCount |
+------+--------+-----------+----+--------+------------+
| 1 | 小刚 | 直男 | 3 | 小刚 | 53 |
| 2 | 小红 | 白富美 | 2 | 小红 | 12 |
| 3 | 小明 | 学霸 | 1 | 小明 | 23 |
| NULL | NULL | NULL | 4 | 小吕 | 123 |
+------+--------+-----------+----+--------+------------+
*/
FULL OUTER JOIN
FULL OUTER JOIN 关键字只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行.相当于结合了 LEFT JOIN 和 RIGHT JOIN 的结果。
但MySQL中不支持 FULL OUTER JOIN。
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name=table2.column_name;
子查询
即SELECT嵌套。
IN
一个查询结果作为另一个查询的条件。如:SELECT * FROM data WHERE name IN (SELECT name FROM user);EXISTS
用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False。True时执行。如:SELECT * FROM data WHERE EXISTS (SELECT name FROM user);
索引
索引的本质是一种排好序的数据结构。利用索引可以提高查询速度。
常见的索引有:
- hash索引
Hash 索引是比较常见的一种索引,他的单条记录查询的效率很高,时间复杂度为1。但Mysql Innodb引擎不支持。
适合精确查找,不适合范围查找:存储引擎为每一行计算一个hash码让后放在hash索引中存储,相邻的数据hash值相差可能很大。 - 二叉树
二叉树的时间复杂度为 O(n)
一个节点只能有两个子节点。且左子节点 < 本节点 < 右子节点
数据量越多,遍历次数越多,IO次数就越多,就越慢。 - B树
每个节点中不仅包含数据的 key 值,还有 data 值。
和二叉树一样,数据多时,导致B树很深,影响查询效率。 - B+树
最常用的索引的数据结构。
B+树比较复杂,可以看此文:MySQL索引原理,一篇从头到尾讲清楚
添加索引
创建时添加
主键
CREATE TABLE test(id TINYINT PRIMARY KEY, name VARCHAR(20)); -- 或 CREATE TABLE test(id TINYINT, name VARCHAR(20), PRIMARY KEY (id)); /* mysql> SHOW CREATE TABLE test; +-------+------------------------------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-------+------------------------------------------------------------------------------------------------------------------------------------------------+ | test | CREATE TABLE `test` ( `id` tinyint(4) NOT NULL, `name` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 | +-------+------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) */非主键
普通索引-- 格式: -- CREATE TABLE <表名> ( <字段> <类型>等 ... , INDEX|KEY [索引名] (<字段名> [长度] [ASC|GESC])); -- | 表示或 CREATE TABLE test (name VARCHAR(20), INDEX n (name)); /* mysql> SHOW CREATE TABLE test; +-------+------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-------+------------------------------------------------------------------------------------------------------------------+ | test | CREATE TABLE `test` ( `name` varchar(20) DEFAULT NULL, KEY `n` (`name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 | +-------+------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) */UNIQUE、FULLTEXT、SPATIAL索引
这三个分别对应唯一索引、全文索引、多列索引。-- CREATE TABLE <表名> ( <字段> <类型>等 ... , -- UNIQUE | FULLTEXT | SPATIAL [ INDEX | KEY] [索引名] [索引类型] (<字段名>,…) CREATE TABLE test(name VARCHAR(20), UNIQUE INDEX(name)); /* mysql> show create table test; +-------+----------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-------+----------------------------------------------------------------------------------------------------------------------------+ | test | CREATE TABLE `test` ( `name` varchar(20) DEFAULT NULL, UNIQUE KEY `name` (`name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 | +-------+----------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) */
创建后追加
/*
原表
mysql> desc test;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | tinyint(4) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
*/
主键
ALTER TABLE test ADD PRIMARY KEY (id); /* mysql> desc test; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | tinyint(4) | NO | PRI | NULL | | | name | varchar(20) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ */非主键索引
普通索引-- 格式和上面的一样 ALTER TABLE test ADD INDEX(name);UNIQUE、FULLTEXT、SPATIAL索引
-- 格式和上面的一样 ALTER TABLE test ADD UNIQUE INDEX(name);
删除索引
非主键索引
-- 格式: -- DROP INDEX <索引名> ON <表名>; DROP INDEX name ON test;主键
-- 格式: -- ALTER TABLE <表名> DROP PRIMARY KEY; ALTER TABLE test DROP PRIMARY KEY;
外键
MySQL通过外键约束来保证表与表之间的数据的完整性和准确性。
外键的使用条件:
- 两个表必须是InnoDB表
- 外键列必须建立了索引,MySQL 4.1.2以后的版本在建立外键时会自动创建索引
- 外键关系的两个表的列必须是数据类型相似,如int和tinyint可以,但int和char则不可以
外键的好处:可以使得两张表关联,保证数据的一致性和实现一些级联操作。
外键创建
-- 表1字表,表2主表
CREATE TABLE <表1名称>
(
O_Id int NOT NULL,
OrderNo int NOT NULL,
P_Id int,
PRIMARY KEY (O_Id), -- 主键也可在字段后面创建
FOREIGN KEY (P_Id) REFERENCES <表2名称>(<表2的ID>)
);
-- user表
CREATE TABLE user(
id TINYINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
-- data表
CREATE TABLE data(
id TINYINT PRIMARY KEY AUTO_INCREMENT,
loginCount TINYINT,
uid TINYINT,
FOREIGN KEY (uid) REFERENCES user(id)
);
增加外键
对已有的两个表增加外键
比如:主表为A,子表为B,外键为aid,外键约束名字为a_fk_b
为子表添加一个字段,当做外键
ALTER TABLE B ADD aid TINYINT;为子表添加外键约束条件
-- 注意对应上 ALTER TABLE B ADD CONSTRAINT a_fk_b FOREIGN KEY(aid) REFERENCES A(id);
删除外键
删除外键约束条件
ALTER TABLE <表名> DROP FOREIGN KEY <外键约束的名字>; ALTER TABLE data DROP FOREIGN KEY data_ibfk_1;外键约束的名字需要通过
SHOW CREATE TABLE命令查看外键
先删除外键约束条件,再删外键字段
第一步在上面
第二步使用命令:ALTER TABLE <表名> DROP <外键字段名>;删除记录
假如删除记录报错:[Err] 1451 -Cannot deleteorupdatea parent row: aforeignkeyconstraintfails (...)
这是因为MySQL中设置了foreign key关联,造成无法更新或删除数据。可以通过设置FOREIGN_KEY_CHECKS变量来避免这种情况。
第一步:禁用外键约束,我们可以使用:SETFOREIGN_KEY_CHECKS=0;
第二步:删除数据
第三步:启动外键约束,我们可以使用:SETFOREIGN_KEY_CHECKS=1;
查看当前FOREIGN_KEY_CHECKS的值,可用如下命令:SELECT @@FOREIGN_KEY_CHECKS;
练习
练习题来源于:sql语句练习50题(Mysql版)