最近想要学习
SQLAlchemy, 发现网上的中文文档好像不是很准确, 读起来特别变扭, 因此对照着最新的英文文档梳理了一遍, 写下来记录一下
安装
$pip install sqlalchemy
检测sqlalchemy版本:
>>>import sqlalchemy
>>>sqlalchemy.__version__
'1.4.27'
使用步骤
一般来说SQLAlchemy的使用方式有两种: Core和ORM
两种有什么不同呢?
ORM是构建在Core之上的Core更加底层, 可以执行直接执行SQL语句ORM类似于Django的ORM, 由于sqlalchemy提供了一套接口, 所以不需要我们直接写SQL语句- 至于要用哪个, 等到你用到时, 你会知道的
官方文档的组件依赖关系图: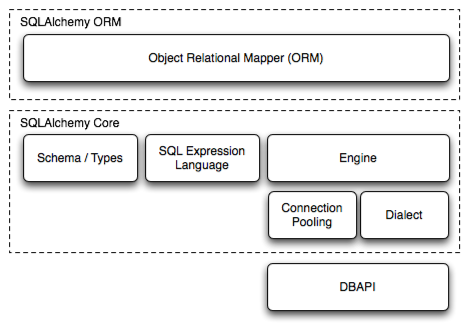
Core
一般来说, 使用步骤如下:
- 配置数据库连接
- 建立连接
- 创建表
- 执行SQL语句, 按需开启事件是否自动提交
- 拿到返回数据, 执行其他代码
数据库的连接的格式
我们在创建引擎(连接)时, 需要指定数据库的URL, URL格式, 见: Engine Configuration
, 总的来说, 格式就是: dialect[+driver]://user:password@host/dbname[?key=value..]
dialect数据库名称: 如mysqldriver连接数据库的库: 如: pymysqluser用户名password密码host地址dbname数据库名称key=value指的是给数据库的参数
如下面的URL:
mysql+pymysql://root:passwd@127.0.0.1:3306/flaskdemo?charset=utf8
建立连接
调用sqlalchemy.create_engine方法, 为了兼容2.0风格的接口, 可以加上future参数. 至于什么是2.0风格的接口, 可以看看官方文档: 2.0 style
create_engine有几个参数需要我们注意:
url即数据库url, 其格式见上文: 数据库的连接的格式echo参数为True时, 将会将engine的SQL记录到日志中 ( 默认输出到标准输出)echo_pool为True时,会将连接池的记录信息输出future使用2.0样式Engine和Connection API
更多参数见官方文档: sqlalchemy.create_engine
例子
from sqlalchemy import create_engine
# 兼容2.0的写法
# 返回对象不一样
engine1 = create_engine("sqlite+pysqlite:///:memory:", echo=True, future=True)
print(type(engine1))
# <class 'sqlalchemy.future.engine.Engine'>
engine2 = create_engine("sqlite+pysqlite:///:memory:", echo=True)
print(type(engine2))
# <class 'sqlalchemy.engine.base.Engine'>
注意, 由于
sqlalchemy使用lazy initialization的策略连接数据库, 故此时还未真正地连接上数据库
创建表
我们想要让数据库创建一个表, 需要利用MetaData对象MetaData是包含Table和Engine的对象, 也就是说它主要是用来管理Table (表)的
下面列出MetaData对象的一些方法
| 方法 | 参数 | 描述 |
|---|---|---|
clear |
无 | 清除此元数据中的所有表对象 |
create_all(bind=None, tables=None, checkfirst=True) |
bind: 数据库Engine tables: Table对象列表 checkfirst: 是否 仅不存在表时 创建 |
在数据库中创建 元数据中的所有表 |
drop_all(bind=None, tables=None, checkfirst=True) |
bind: 数据库Engine tables: Table对象列表 checkfirst: 是否 仅存在表时 删除 |
在数据库中删除 元数据中存储的所有表 |
remove(table) |
table: 表对象 |
从此元数据中删除给定的表对象 |
tables |
tables是属性, 无参数 |
返回Table的字段对象 |
除了要MetaData对象外, 我们还需要Table对象, 用于定义一个表的结构Table的一般使用
mytable = Table("mytable", metadata,
Column('mytable_id', Integer, primary_key=True),
Column('value', String(50))
)
Table的参数:
name表名称metadata该表所属的MetaData对象- 其他参数: 通过
Column指定一列数据, 格式见: Column定义
例子:
from sqlalchemy import MetaData, Table, Column, Integer, String, ForeignKey
from sqlalchemy import create_engine, text
# 数据库配置
DATABASE_CONFIG = {
"username": "root",
"password": "123456",
"host": "localhost",
"database": "test"
}
# 连接mysql
engine = create_engine("mysql+pymysql://{username}:{password}@{host}/{database}".format(**DATABASE_CONFIG),
echo=True, future=True)
metadata_obj = MetaData()
user_table = Table(
"user_account",
metadata_obj,
Column('id', Integer, primary_key=True),
Column("username", String(30))) # String也可以不实例化
# 第二个表
address_table = Table(
"address",
metadata_obj,
Column("id", Integer, primary_key=True),
Column("uid", ForeignKey("user_account.id"), nullable=False),
Column('email_address', String(32), nullable=False)
)
# 相当于执行 CREATE TABLE 语句
metadata_obj.create_all(engine)
"""
-- 相当于:
CREATE TABLE user_account (
id INTEGER NOT NULL AUTO_INCREMENT,
username VARCHAR(30),
PRIMARY KEY (id)
);
CREATE TABLE address (
id INTEGER NOT NULL AUTO_INCREMENT,
uid INTEGER NOT NULL,
email_address VARCHAR(32) NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY(uid) REFERENCES user_account (id)
)
"""
create_all方法, 默认会在创建表之间检测一下表是否存在, 不存在时才创建.
# .c => Column
print(user_table.c.keys())
# ['id', 'username']
print(repr(user_table.c.username))
# Column('username', String(length=30), table=<user>)
print(user_table.primary_key)
# 隐式生成
# PrimaryKeyConstraint(Column('id', Integer(), table=<user>, primary_key=True, nullable=False))
在事务中执行SQL
通常, 我们通过engine.connect和engine.begin开始一个事件sqlalchemy使用事务有两种风格commit as you go和Begin once, 前者需要我们手动提交, 后者会自动提交
手动提交
engine.connect方法符合python的上下文管理协议, 会返回一个Connection对象, 该方法会在不手动提交的情况下回滚.举个例子:
from sqlalchemy import create_engine
from sqlalchemy import text
# 数据库配置
DATABASE_CONFIG = {
"username": "root",
"password": "123456",
"host": "localhost",
"database": "test"
}
# 连接mysql
engine = create_engine("mysql+pymysql://{username}:{password}@{host}/{database}".format(**DATABASE_CONFIG),
echo=True, future=True)
with engine.connect() as conn:
# 执行
result = conn.execute(text("select 'hello world'")) # text 可以使用SQL语句
print(result.all())
# conn.commit()
# [('hello world',)]
# 最后会ROLLBACK
上面的代码中, 相当于开启了事务, 由于最后没有调用commit方法, 所以会回滚.
自动提交
engine.begin方法也符合python的上下文管理协议, 只要执行时不报错就会自动提交, 报错时会回滚.
from sqlalchemy import create_engine
from sqlalchemy import text
# 数据库配置
DATABASE_CONFIG = {
"username": "root",
"password": "123456",
"host": "localhost",
"database": "test"
}
# 连接mysql
engine = create_engine("mysql+pymysql://{username}:{password}@{host}/{database}".format(**DATABASE_CONFIG),
echo=True, future=True)
with engine.begin() as conn:
result = conn.execute(text("select 'hello world'"))
print(result.all())
# [('hello world',)]
# COMMIT
绑定参数
上面在事务中执行SQL语句时, 我们用到了sqlalchemy.text, 可以直接定义文本SQL字符串
为了避免被SQL注入, 故在需要传入参数的场景中需要根据sqlalchemy的方式传入, 而不是直接拼接成字符串.
使用:y的格式定义参数, 且将值以字典的形式传给execute
from sqlalchemy import create_engine
from sqlalchemy import text
# 数据库配置
DATABASE_CONFIG = {
"username": "root",
"password": "123456",
"host": "localhost",
"database": "test"
}
# 连接mysql
engine = create_engine("mysql+pymysql://{username}:{password}@{host}/{database}".format(**DATABASE_CONFIG),
echo=True, future=True)
with engine.begin() as conn:
result = conn.execute(text("select name from userinfo where name like :y"), {"y": "lcz%"})
print(result.all())
# [('lczmx',)]
# COMMIT
多个参数时, 可以这样:
with engine.connect() as conn:
conn.execute(
text("INSERT INTO userinfo (id, name) VALUES (:x, :y)"),
[{"x": 1, "y": "lcmx"}, {"x": 2, "y": "xxx"}])
conn.commit()
这种方式也可以:
stmt = text("SELECT x, y FROM some_table WHERE y > :y ORDER BY x, y").bindparams(y=6)
with engine.connect() as conn:
conn.execute(stmt)
conn.commit()
execute返回的数据
我们执行conn.execute命令的结果为: CursorResult对象
| 方法 | 参数 | 描述 |
|---|---|---|
fetchone |
无 | 取一行数据, 当所有行都用完时,返回None |
one |
无 | 只返回一行数据或引发异常 |
first |
无 | 获取第一行数据,关闭结果集并丢弃其余行, 如果没有行,则不获取 |
all |
无 | 返回列表中的所有行数据, 调用后关闭 CursorResult, 随后的调用将返回一个空列表 |
fetchmany |
size: 取多少行数据 |
取多行数据, 当所有行都用完时, 返回一个空列表 |
columns |
col_expressions |
建立每行数据中应返回的列 |
close |
无 | 关闭此CursorResult |
一行数据是一个Row对象
| 属性/方法 | 属性或方法 | 描述 |
|---|---|---|
_asdict |
方法 | 返回字段名与值的字典数据 并添加到_mapping属性 |
_fields |
属性 | 返回字符名的元组 |
_mapping |
属性 | 返回字段名与值的字典数据 |
例子,假如mysql中的表:
mysql> select * from user_account;
+----+----------+
| id | username |
+----+----------+
| 9 | lczmx |
| 10 | jack |
| 11 | tom |
| 12 | mike |
+----+----------+
4 rows in set (0.00 sec)
mysql>
利用SQLAlchemy获取数据:
from sqlalchemy import MetaData, Table, Column, Integer, String, ForeignKey
from sqlalchemy import create_engine, text
# 数据库配置
DATABASE_CONFIG = {
"username": "root",
"password": "123456",
"host": "localhost",
"database": "test"
}
# 连接mysql
engine = create_engine("mysql+pymysql://{username}:{password}@{host}/{database}".format(**DATABASE_CONFIG),
echo=True, future=True)
with engine.connect() as conn:
# 执行
result = conn.execute(text("select * from user_account;"))
for row in result.all():
# 使用f-strings 格式化字符串
print(f"id: {row.id:3}, username: {row.username:20}")
# 打印的结果:
"""
id: 9, username: lczmx
id: 10, username: jack
id: 11, username: tom
id: 12, username: mike
"""
conn.commit()
ORM
和Core一样, ORM也有一定的使用步骤:
- 配置数据库连接, 见上文: 数据库的连接的格式
- 创建会话
- 创建表
- 使用接口, 增删改查数据
- 拿到返回数据, 执行其他代码
在学习SQLAlchemy的ORM之前, 建议先了解一些概念, 以免后面会混淆
- 会话
Session
会话是SQLAlchemy ORM和数据库交互的方式
它通过引擎包装数据库连接, 并为通过会话加载或与会话关联的对象提供标识映射 (identity map) - Base
使用
ORM时, 事务/数据库交互对象称为Session, 在使用时与Connection非常相似
在sqlalchemy中, session是一个连接池, 建立连接中的engine由其管理, 因此, 假如我们需要操作数据库的话, 需要在session中拿到Connection(连接)
在使用Session.execute()方法时Connection.execute()非常相似,包括 ORM 结果行使用 Core 使用的同一个 Result 接口交付。
创建会话
SQLAlchemy提供了两种创建会话的方法:
sqlalchemy.orm.Sessionfrom sqlalchemy import create_engine from sqlalchemy.orm import Session # 创建引擎 engine = create_engine('postgresql://scott:tiger@localhost/') # 创建会话 # 以下with可以简写成 with Session(engine) as session, session.begin(): with Session(engine) as session: # 开启自动提交 with session.begin(): # add方法 会将some_object 保存到数据库 # session.add(some_object) # session.add(some_other_object) passsqlalchemy.orm.sessionmakerfrom sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker # 创建引擎 engine = create_engine('postgresql://scott:tiger@localhost/') # 创建session Session = sessionmaker(engine) # 一般使用 with Session() as session: # session.add(some_object) # session.add(some_other_object) # 提交 session.commit() # 自动提交 with Session.begin() as session: # session.add(some_object) # session.add(some_other_object) pass
虽然有两种方法创建会话, 但我们一般使用sessionmaker创建会话
session的方法:
| 方法 | 参数 | 描述 |
|---|---|---|
add |
instance |
下次刷新操作时, 将 instance 保留到数据库中 |
delete |
instance |
下次刷新操作时, 将instance从数据库中删除 |
begin |
subtransactions nested _subtrans |
开始事务 |
rollback |
无 | 回滚当前事务 |
commit |
无 | 提交当前事务 |
close |
无 | 关闭此Session |
execute |
statement params execution_option bind_arguments 等 |
执行SQL表达式构造 |
query |
*entities **kwargs |
返回Query, 可用于查询数据 |
refresh |
instance attribute_names with_for_update |
刷新属性 |
例子:
from sqlalchemy import create_engine, text
from sqlalchemy.orm import Session
# 数据库配置
DATABASE_CONFIG = {
"username": "root",
"password": "123456",
"host": "localhost",
"database": "test"
}
# 连接mysql
engine = create_engine("mysql+pymysql://{username}:{password}@{host}/{database}".format(**DATABASE_CONFIG),
echo=True, future=True)
stmt = text("SELECT id, name FROM userinfo WHERE id > :y").bindparams(y=1)
with Session(engine) as session:
result = session.execute(stmt)
print(result.all())
# [(2, 'name2'), (3, 'name2')]
# ROLLBACK
ORM方式创建表
使用ORM时, 我们也需要MetaData, 不同的是, 我们是通过sqlalchemy.orm.registry构造的, 和使用django orm一样, 我们不需要像Core那样直接声明Table, 而是继承某个公共基类, 添加属性即可. 有两种方式定义基类
方式一:
from sqlalchemy.orm import registry
mapper_registry = registry()
print(mapper_registry.metadata) # MetaData对象
# 公共基类
Base = mapper_registry.generate_base()
方法二:
from sqlalchemy.orm import declarative_base
# 内部 return registry(...).generate_base(...)
Base = declarative_base()
定义表并在数据库中创建表:
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
from sqlalchemy.orm import declarative_base
Base = declarative_base()
# 数据库配置
DATABASE_CONFIG = {
"username": "root",
"password": "123456",
"host": "localhost",
"database": "test"
}
# 连接mysql
engine = create_engine("mysql+pymysql://{username}:{password}@{host}/{database}".format(**DATABASE_CONFIG),
echo=True, future=True)
# 如django orm 一样定义表
class UserAccount(Base):
# 定义表名称
__tablename__ = "user_account"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(30))
# 如CORE一样, 创建表
Base.metadata.create_all(engine)
"""
CREATE TABLE user_account (
id INTEGER NOT NULL AUTO_INCREMENT,
username VARCHAR(30),
PRIMARY KEY (id)
)
"""
注: 你通过
UserAccount.__table__属性可以查看Table
增删改查数据
插入数据
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
from sqlalchemy.orm import declarative_base, sessionmaker
Base = declarative_base()
# 数据库配置
DATABASE_CONFIG = {
"username": "root",
"password": "123456",
"host": "localhost",
"database": "test"
}
# 连接mysql
engine = create_engine("mysql+pymysql://{username}:{password}@{host}/{database}".format(**DATABASE_CONFIG),
echo=True, future=True)
Session = sessionmaker(bind=engine)
# 如django orm 一样定义表
class UserAccount(Base):
# 定义表名称
__tablename__ = "user_account"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(30))
# 如CORE一样, 创建表
Base.metadata.create_all(engine)
user1 = UserAccount(username="小明")
user2 = UserAccount(username="小红")
session = Session()
# 添加到session, 下次刷新时保存到数据库
session.add(user1)
session.add(user2)
session.commit()
# 刷新到数据库
session.refresh(user1)
session.refresh(user2)
总的来说, 保存到数据库的代码一般为:
# 1. 实例化一个表类
db_city = Table(....)
# 2. 调用session的add方法
session.add(db_city)
# 3. 调用session的commit方法 提交事务
session.commit()
# 4. 调用session的refresh方法 将数据刷新到数据库
session.refresh(db_city)
查询数据
我们知道, SQLAlchemy目前有两种风格, 1.x和2.x, 当前SQLAlchemy的版本为1.4, 处于1.x过渡到2.x的时代. 为了尽量让这篇文章的兼容之后的版本, 这里讲述1.x和2.x两种风格的Query接口.
1.xAPI
- TODO
2.xAPI
SQLAlchemy在2.0版和1.4版中最大的概念变化是 Select 核心构造和 Query 对象已被移除
删除数据
- TODO
修改数据
- TODO
项目示范
一般来说, 我们使用SQLAlchemy的步骤大多相同, 下面
文件结构:
+--- database.py # 用于 初始化session 和 公共基类
+--- models.py # 定义表
+--- crud.py # 封装增删改查的方法
+--- schemas.py # 定义pydantic模型, 用于格式化已经取得的数据 [可选]
+--- main.py # 执行主逻辑
database.py:
# database.py 用于 初始化session 和 公共基类
from sqlalchemy import create_engine
from sqlalchemy.orm import declarative_base, sessionmaker
# 数据库的URL
# 替换成自己的
SQLALCHEMY_DATABASE_URL = 'sqlite:///./coronavirus.sqlite3'
# 创建引擎
engine = create_engine(
# echo=True表示引擎将用repr()函数记录所有语句及其参数列表到日志
SQLALCHEMY_DATABASE_URL, encoding='utf-8', echo=True
)
# SessionLocal用于对数据的增删改查
# flush()是指发送数据库语句到数据库,但数据库不一定执行写入磁盘;commit()是指提交事务,将变更保存到数据库文件
SessionLocal = sessionmaker(bind=engine, autoflush=False, autocommit=False, expire_on_commit=True)
# 创建基本映射类, 用于创建表
Base = declarative_base(bind=engine, name='Base')
models.py:
# models.py # 定义表
from sqlalchemy import Column, String, Integer, BigInteger, Date, DateTime, ForeignKey, func
from sqlalchemy.orm import relationship
# 导入公共基类
from .database import Base
class City(Base):
__tablename__ = 'city'
id = Column(Integer, primary_key=True, index=True, autoincrement=True)
province = Column(String(100), unique=True, nullable=False, comment='省/直辖市')
country = Column(String(100), nullable=False, comment='国家')
country_code = Column(String(100), nullable=False, comment='国家代码')
country_population = Column(BigInteger, nullable=False, comment='国家人口')
data = relationship('Data', back_populates='city') # 'Data'是关联的类名;back_populates来指定反向访问的属性名称
created_at = Column(DateTime, server_default=func.now(), comment='创建时间')
updated_at = Column(DateTime, server_default=func.now(), onupdate=func.now(), comment='更新时间')
__mapper_args__ = {"order_by": country_code} # 默认是正序,倒序加上.desc()方法
def __repr__(self):
return f'{self.country}_{self.province}'
class Data(Base):
__tablename__ = 'data'
id = Column(Integer, primary_key=True, index=True, autoincrement=True)
city_id = Column(Integer, ForeignKey('city.id'), comment='所属省/直辖市') # ForeignKey里的字符串格式不是类名.属性名,而是表名.字段名
date = Column(Date, nullable=False, comment='数据日期')
confirmed = Column(BigInteger, default=0, nullable=False, comment='确诊数量')
deaths = Column(BigInteger, default=0, nullable=False, comment='死亡数量')
recovered = Column(BigInteger, default=0, nullable=False, comment='痊愈数量')
city = relationship('City', back_populates='data') # 'City'是关联的类名;back_populates来指定反向访问的属性名称
created_at = Column(DateTime, server_default=func.now(), comment='创建时间')
updated_at = Column(DateTime, server_default=func.now(), onupdate=func.now(), comment='更新时间')
__mapper_args__ = {"order_by": date.desc()} # 按日期降序排列
def __repr__(self):
return f'{repr(self.date)}:确诊{self.confirmed}例'
crud.py:
# crud.py # 封装增删改查的方法
from sqlalchemy.orm import Session
import models
import schemas
def get_city(db: Session, city_id: int):
return db.query(models.City).filter(models.City.id == city_id).first()
def get_city_by_name(db: Session, name: str):
return db.query(models.City).filter(models.City.province == name).first()
def get_cities(db: Session, skip: int = 0, limit: int = 10):
return db.query(models.City).offset(skip).limit(limit).all()
def create_city(db: Session, city: schemas.CreateCity):
"""
创建City数据
"""
db_city = models.City(**city.dict())
db.add(db_city)
db.commit()
db.refresh(db_city)
return db_city
def get_data(db: Session, city: str = None, skip: int = 0, limit: int = 10):
if city:
# 外键关联查询,这里不是像Django ORM那样Data.city.province
return db.query(models.Data).filter(models.Data.city.has(province=city))
return db.query(models.Data).offset(skip).limit(limit).all()
def create_city_data(db: Session, data: schemas.CreateData, city_id: int):
"""
创建Data数据
"""
db_data = models.Data(**data.dict(), city_id=city_id)
db.add(db_data)
db.commit()
db.refresh(db_data)
return db_data
schemas.py:
# schemas.py # 定义pydantic模型, 用于格式化已经取得的数据 [可选]
from datetime import date as date_
from datetime import datetime
from pydantic import BaseModel
class CreateData(BaseModel):
date: date_
confirmed: int = 0
deaths: int = 0
recovered: int = 0
class CreateCity(BaseModel):
province: str
country: str
country_code: str
country_population: int
class ReadData(CreateData):
id: int
city_id: int
updated_at: datetime
created_at: datetime
class Config:
orm_mode = True
class ReadCity(CreateCity):
id: int
updated_at: datetime
created_at: datetime
class Config:
orm_mode = True
main.py:
# main.py # 执行主逻辑
from sqlalchemy.orm import Session
import crud
import schemas
from database import engine, Base, SessionLocal
from models import City, Data
# 创建表, 已经存在的将被忽略
Base.metadata.create_all(bind=engine)
db = SessionLocal()
# 调用 crud
db_city = crud.get_city_by_name(db, name="广东省")
if db_city:
raise Exception("City already registered")
# 创建数据
city = City(...)
crud.create_city(db=db, city=city)
一些类的介绍
Result
表示一组数据
该类位于sqlalchemy.engine.Result,有了这个类, 可以让Core和ORM的结果的API相一致
方法:
allcolumns(*col_expressions)fetchall()fetchmany(size=None)fetchone()first()freeze()keys()mappings()merge(*others)one()one_or_none()partitions(size=None)scalar()scalar_one()scalar_one_or_none()scalars(index=0)unique(strategy=None)yield_per(num)
Row
如何使用见: fetching-rows
数据迁移工具
使用alembic,见另一篇文章
日志
Column定义
一般使用
一个Column即表的一列数据, 和我们用SQL语句定义一列数据一样, 参数主要包括: 字段名、字段类型、约束条件, 比如:
from sqlalchemy import Column, String
Column("name", String(30), unique=True, nullable=False, comment='姓名')
字段类型, 一般你可以用直接指定数据库的字段类型, 也可以让SQLAlchemy的DDL自动选择字段类型
直接使用数据库的字段类型
| 字段类型 | 描述 |
|---|---|
ARRAY(item_type, ...) |
数组类型, 目前只支持PostgreSQL, 因此建议用: sqlalchemy.dialects.postgresql.ARRAY |
BIGINT |
SQL BIGINT类型 |
BINARY(length) |
SQL BINARY类型 |
BLOB |
SQL BLOB类型 |
BOOLEAN |
SQL布尔类型 |
CHAR |
SQLCHAR类型 |
CLOB |
SQL CLOB型 |
DATE |
SQL DATE期类型 |
DATETIME |
SQL DATETIME类型 |
DECIMAL |
SQL DECIMAL类型 |
FLOAT |
SQL FLOAT类型 |
INT |
sqlalchemy.sql.sqltypes.INTEGER的别名 |
INTEGER |
SQL INT或INTEGER类型 |
JSON |
SQL JSON类型 |
NCHAR |
SQL NChar类型 |
NUMERIC |
SQL NUMERIC类型 |
NVARCHAR |
SQL NVARCHAR类型 |
REAL |
SQL REAL类型 |
SMALLINT |
SQL SMALLINT类型 |
TEXT |
SQL TEXT类型 |
TIME |
SQL TIME类型 |
TIMESTAMP |
SQL TIMESTAMP类型 |
VARBINARY |
SQLVARBINARY类型 |
VARCHAR |
SQL VARCHAR类型 |
关于SQL的数据类型, 见: SQL 数据类型
自动转化的字段类型:
| 字段类型 | 描述 | 通常对应的字段类型 |
|---|---|---|
Boolean |
布尔数据类型 | Boolean或SMALLINT |
String |
所有字符串和字符类型的基 | VARCHAR |
Text |
大小可变的字符串类型 | CLOB或TEXT |
LargeBinary |
大的二进制字节数据类型 | BLOB或BYTEA |
Unicode |
长度可变的Unicode字符串类型 | |
UnicodeText |
无限长的Unicode字符串类型 | |
SmallInteger |
较小的一种 int 整数 | SMALLINT |
Integer |
int类型 | |
BigInteger |
BIGINT数据类型 | BIGINT |
Numeric |
用于固定精度数字的类型 | NUMERIC或DECIMAL |
Float |
浮点类型 | FLOAT 或 REAL . |
Date |
datetime.date类型 |
|
Time |
datetime.time类型 |
|
DateTime |
datetime.datetime类型 |
|
Interval |
datetime.timedelta类型 |
|
Enum |
枚举类型 | ENUM或VARCHAR |
PickleType |
保存使用pickle序列化的python对象 | 二进制类型 |
SchemaType |
将类型标记为可能需要架构级DDL才能使用 | |
MatchType |
引用match运算符的返回类型 | MySQL的是浮点型 |
约束条件:
| 约束条件和其他参数 | 描述 |
|---|---|
autoincrement |
是否自增 |
default |
设置默认参数 |
index |
是否创建索引 |
info |
SchemaItem.info的属性 |
nullable |
是否非空, False时not null |
primary_key |
是否为主键 |
unique |
是否唯一 |
comment |
注释字段 |
onupdate |
调用更新数据时的默认值, 如: updated_at = Column(DateTime, server_default=func.now(), onupdate=func.now()) |
server_default |
为SQLAlchemy的DDL设置默认值, 可以是str unicode text(), 如: sqlalchemy.func.now() |
注 :
sqlalchemy.func, 用于生成SQL函数表达式
使用外键
子表使用字段名= Column(Integer, ForeignKey('主表名.主键'))的格式定义
除此外, 还需要定义relationship用于访问子表或主表
完整例子:
from sqlalchemy import create_engine
from sqlalchemy.orm import declarative_base, relationship
from sqlalchemy import Column, String, Integer, BigInteger, Date, DateTime, ForeignKey, func
Base = declarative_base()
# 数据库配置
DATABASE_CONFIG = {
"username": "root",
"password": "123456",
"host": "localhost",
"database": "test"
}
# 连接mysql
engine = create_engine("mysql+pymysql://{username}:{password}@{host}/{database}?charset=utf8".format(**DATABASE_CONFIG),
echo=True, future=True)
class City(Base):
__tablename__ = 'city' # 数据表的表名
id = Column(Integer, primary_key=True, index=True, autoincrement=True)
province = Column(String(100), unique=True, nullable=False, comment='省/直辖市')
# 'Data' 是关联的类名;back_populates来指定反向访问的属性名称
data = relationship('Data', back_populates='city')
class Data(Base):
__tablename__ = 'data'
id = Column(Integer, primary_key=True, index=True, autoincrement=True)
# ForeignKey里的字符串格式不是类名.属性名,而是表名.字段名
city_id = Column(Integer, ForeignKey('city.id'), comment='所属省/直辖市')
date = Column(Date, nullable=False, comment='数据日期')
# 'City' 是关联的类名;back_populates来指定反向访问的属性名称
city = relationship('City', back_populates='data')
Base.metadata.create_all(engine)